With the arrival of Manifold CF 1.0 (now already in v1.6.1), the open source community is looking for tutorials to combine it with Elasticsearch. That’s the intent of this tutorial, which will drive you through the different steps required to make it work.
First, we’ll recap the installation process of Manifold CF (we’ll call it MCF later on). Second, we will install ElasticSearch with the attachment plugin so that it handles rich document indexing. Third, we’ll configure MCF so that it crawls a windows file share and indexes documents in ElasticSearch. In this tutorial, when I specify installation directory such as apache-manifoldcf-1.6.1, you have to complete with the absolute path of the installation directory.
Installing ManifoldCF:
We will install and deploy Manifold CF on tomcat with PostGre SQL DB, which is the recommanded DB for Manifold CF deployment in production environnement.
- First download the last released version of MCF (tested with Apache Manifold CF 1.6.1) and unzip it.
- You also have to download the jcifs library to crawl Samba share (tested with jcifs-1.3.17). Download and copy/paste the jcifs-1.3.17.jar into:
apache-manifoldcf-1.6.1\connector-lib-proprietary
- Download version 9.3 of PostgreSQL. Install it with the installer.
In
apache-tomcat-8.0.8\conf\Catalina\localhost
create 3 xml files: mcf-api-service.xml, mcf-authority-service.xml and mcf-crawler-ui.xml (you will probably have to create the Catalina and localhost directories).
In mcf-api-service.xml, add the following code:
<xmlversion="1.0"encoding="utf-8"?> <Context docBase="apache-manifoldcf-1.6.1\web\war\mcf-api-service.war" crossContext="true"> </Context>
Do the same operation for mcf-authority-service.xml and mcf-crawler-ui.xml.
Edit
apache-manifoldcf-1.6.1\connectors.xml
in this file you need to uncomment:
<repositoryconnector name="Windows shares" class="org.apache.manifoldcf.crawler.connectors.sharedrive.SharedDriveConnector" />
Edit
apache-manifoldcf-1.6.1\multiprocess-file-example\properties.xml
The first five properties can be commented because they are only useful for a jetty server.
Modify the database implementation class in order to use postgre instead of derby:
<propertyname="org.apache.manifoldcf.databaseimplementationclass" value="org.apache.manifoldcf.core.database.DBInterfacePostgreSQL"/>
Add a line to specify the database name, the specified database shoudn’t exist for the moment in the postgresql server.
<propertyname="org.apache.manifoldcf.database.name"value="manifoldcf"/>
Modify the username and password:
<propertyname="org.apache.manifoldcf.dbsuperusername"value="postgres"/
propertyname="org.apache.manifoldcf.dbsuperuserpassword"value="password"/>
You can now initialize your database with the following script. This script will automatically create the database and tables that will be used by the crawler:
apache-manifoldcf-1.6.1\multiprocess-file-example\initialize.bat
Now set the classpath values with the following script:
apache-manifoldcf-1.6.1\multiprocess-file-example\setclasspath.bat
Edit
apache-tomcat-8.0.8\bin\startup.bat
Add the following line at the beginning of the file to point the configuration file for MCF :
set "CATALINA_OPTS=-Dorg.apache.manifoldcf.configfile=apache-manifoldcf-1.6.1\multiprocess-example\properties.xml\properties.xml"
Installing ElasticSearch with the attachment plugin
Unzip elasticsearch-1.2.1.zip.
Run
elasticsearch-1.2.1/bin/plugin.bat -install elasticsearch/elasticsearch-mapper-attachments/2.0.0
to download the attachment plugin. It will be automatically installed during the next startup of Elasticsearch.
Start Elasticsearch:
elasticsearch-1.2.1/bin/elasticsearch.bat
Create the new index “fileshare”. You can use curl for windows or any client that run REST commands:
curl -X PUT "localhost:9200/fileshare" -d '{
"settings" : { "index" : { "number_of_shards" : 1, "number_of_replicas" : 0 }}
}'
Now we will have to add a mapping configuration that creates the document type “file” that uses the attachment plugin to handle rich documents:
curl -X PUT "192.168.0.82:9200/fileshare/file/_mapping" -d '{
"file" : {
"properties" : {
"file" : {
"type" : "attachment"
}
}
}
}'
Configuring Manifold CF and crawling:
Start the agents that are in charge of crawling the data:
apache-manifoldcf-1.6.1\ multiprocess-file-example\start-agents.bat
Start Tomcat. Go to the admin interface : http://localhost:8080/mcf-crawler-ui/
By default, the credentials are admin/admin.
In Output -> List Output Connections, select Add a new output connection
Type a name : “ElasticSearch” then select ElasticSearch for type and continue.
In the parameters tab, change index name to fileshare and index type to file.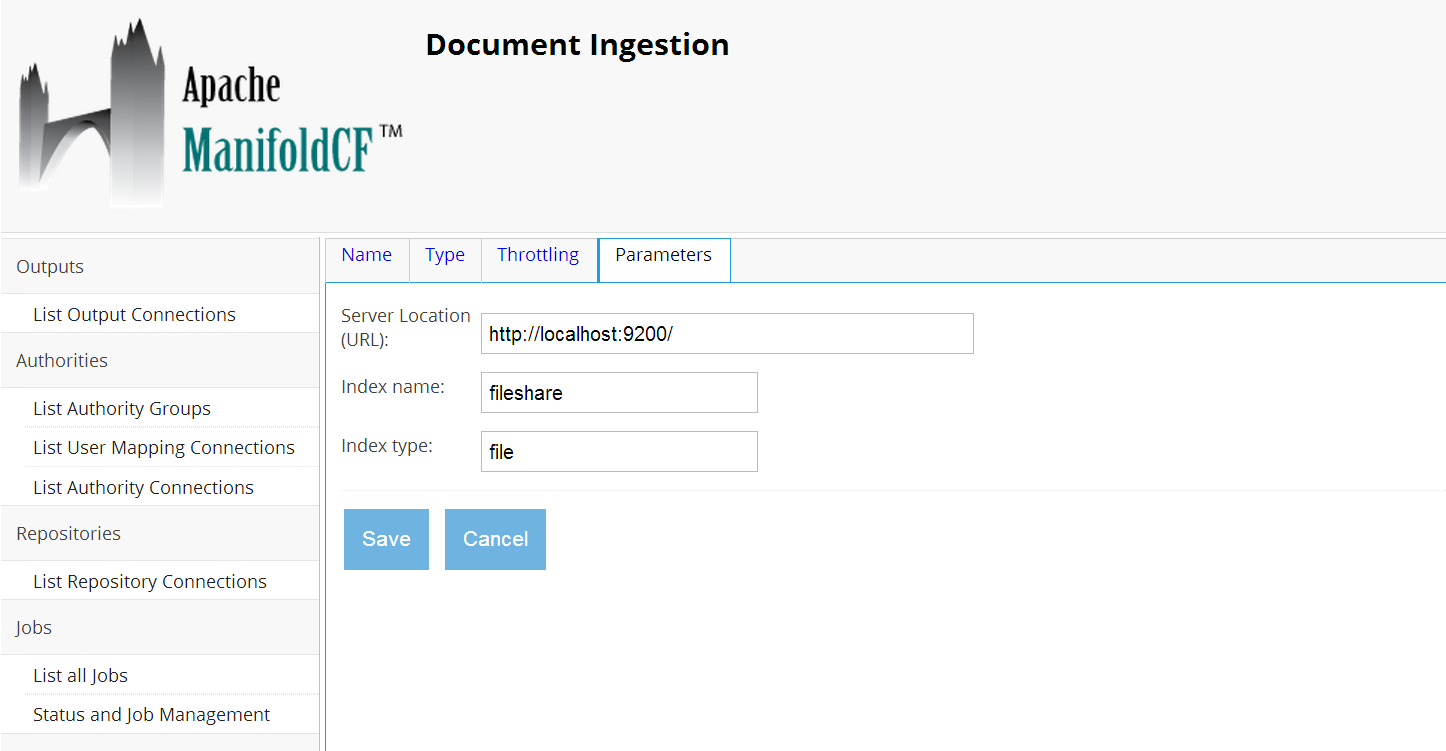
Click on Save, you should have Connection status:Connection working.
In Repositories -> List Repository Connections, select Add a new connection
Type a name : “FileShare” then select Windows Share for type and continue.
In the Server tab, enter the information of your windows server, (hostname, domain, username and password).
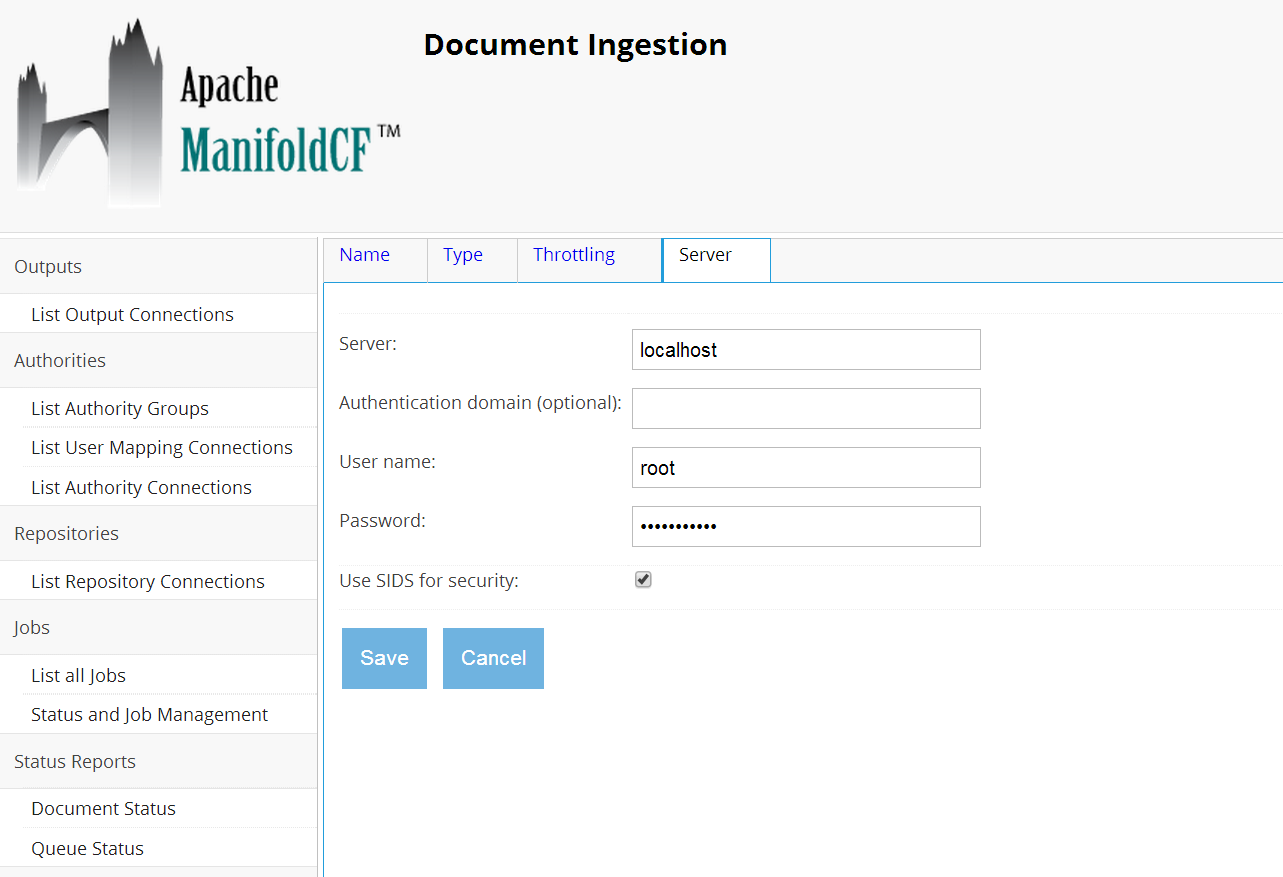
Click on Save, you should have Connection status:Connection working.
In Jobs -> List all Jobs, select Add a new job,
Select a name, “CrawlFile”, in Connection tab, select ElasticSearch for the Output connection and FileShare for the repository connection.
Click on continue and go to Paths.
Select your folder and Click on +. Then click on Add. You should have:
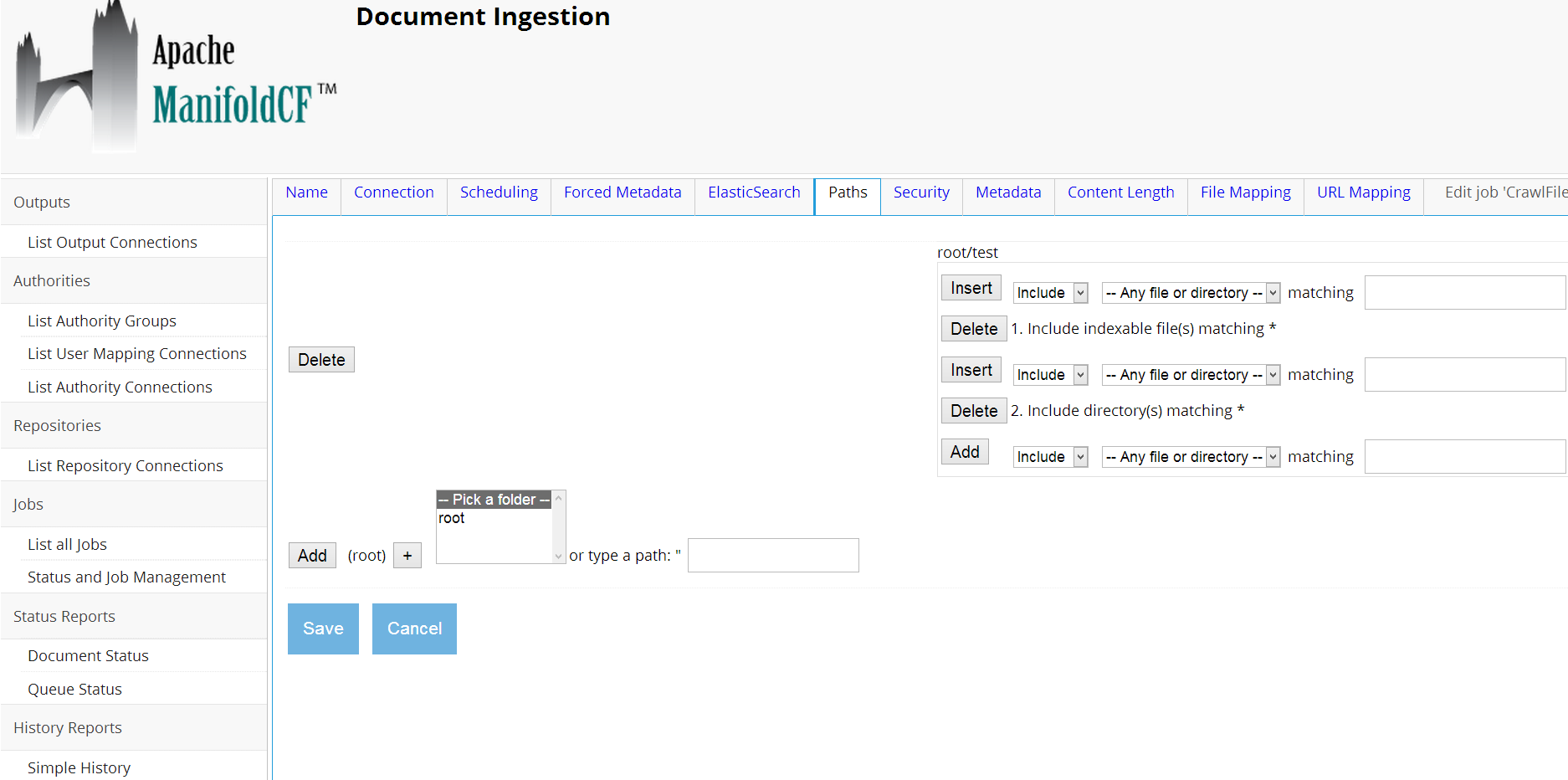
Click on Save and go to Jobs -> Status and Job Management
Start your job and wait until it ends:
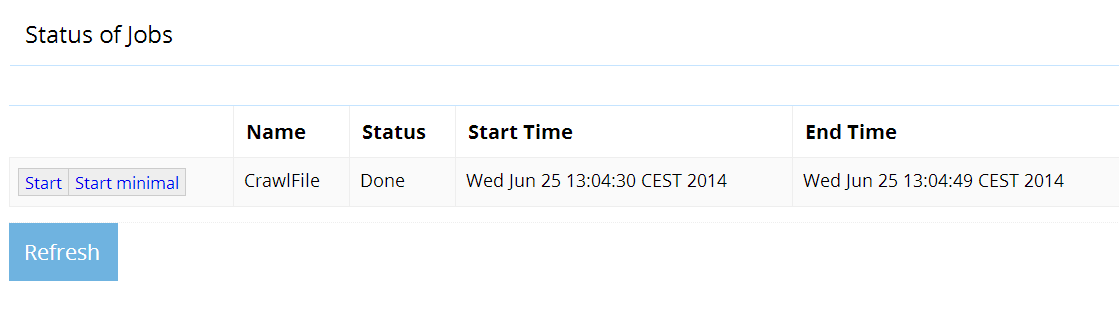
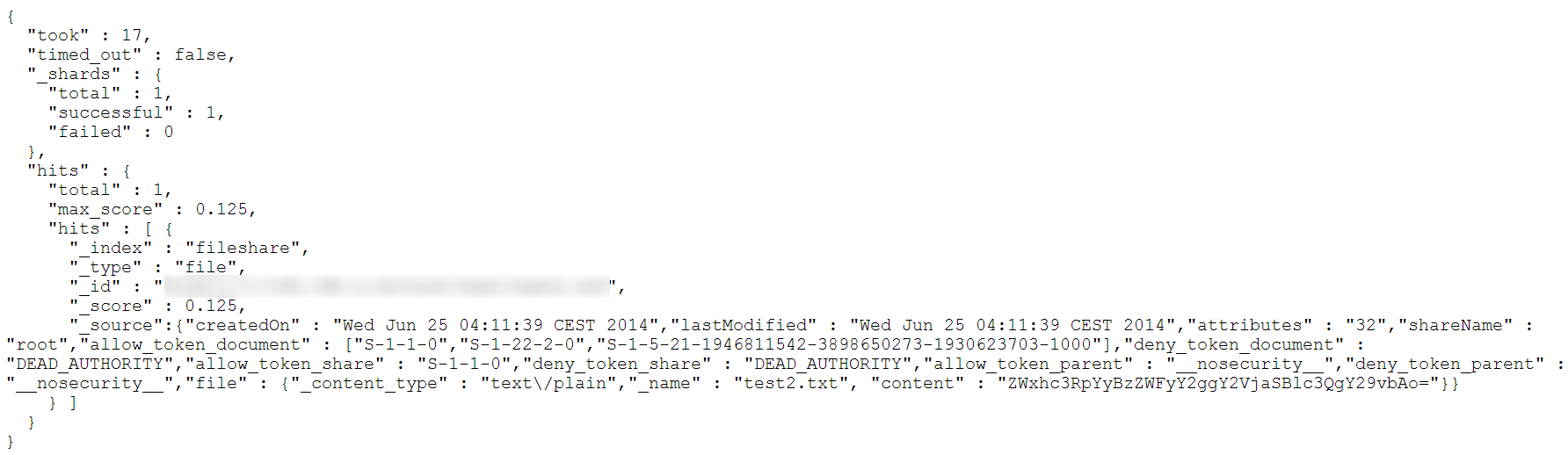
You can now perform a search with ElasticSearch. For instance we can now search (and find) the document in our fileshare which contains the word “search”:
http://localhost:9200/fileshare/_search?q=search&pretty=true